
1. 인공지능, 머신러닝, 딥러닝
인공지능, 머신러닝, 딥러닝 모두 비슷한 것 처럼 들리겠지만 서로 다른 개념이다.


왼쪽 사진 출처: NDIVIA
AI는 인간의 학습능력, 추론능력, 지각능력 등을 인공적으로 구현하려는 컴퓨터 과학의 세부분야 중 하나이며,
머신러닝은 오늘 날 인공지능을 구현하는 가장 유망하고 유명한 분야이다.
머신러닝은 지도학습과 비지도학습으로 나눌 수 있는데(추가적으로 강화학습도 있다.)
이 둘의 차이는 정답값의 유무이다.
지도학습은 정답값이 있는 경우의 학습으로 회귀와 분류문제를 다루며 (회귀 - 수치형, 분류 - 범주형)
비지도 학습은 정답값이 없는 경우의 학습으로 차원축소와 군집화의 문제를 해결할 수 있다.
그리고 다시 회귀와 분류 문제를 해결하기 위한 알고리즘으로
Decision Tree, Random Forest (DT의 앙상블버전), KNN, SVM, Neural network 등이 있는데
이 중 Neural network를 사용하는 학습이 바로 "딥러닝"이다.
딥러닝(Neural network)을 코딩으로 구현할 수 있도록 하는 라이브러리로는
tensorflow, pytorch, caffe, Theano 등이 존재한다.

사진 출처: https://www.epnc.co.kr/news/articleView.html?idxno=91752
2. 딥러닝 역사

출처: https://sefiks.com/2017/10/14/evolution-of-neural-networks/

출처: https://post.naver.com/viewer/postView.naver?volumeNo=32532719&memberNo=25379965&vType=VERTICAL
3. 퍼셉트론
퍼셉트론은 인공 신경망의 한종류로서, 가장 단순한 형태의 순방향 신경망 네트워크인 "선형 분류기"로도 볼 수 있다.

x1, x2: 입력값
y: 출력값
w1, w2: 가중치
b: 편향
y = activation(w1x1 + w2x2 + b)
각 노드의 가중치와 입력치를 곱한 것을 모두 합한 값이 활성함수에 의해 판단되는데,
그 값이 임계치(보통 0)보다 크면 뉴런이 활성화되고 결과값으로 1을 출력하고
그 값이 임계치보다 작으면 뉴러니 활성화되지 않고 결과값으로 -1을 출력한다.
1️⃣ 단층퍼셉트론
입력층과 출력층으로 구성되며
단층 퍼셉트론을 사용할 경우, 하나의 선으로 0과 1을 분리하지 못하는 XOR 문제에 직면하면서 AI는 암흑기를 맞이함
XOR 문제

출처: https://extsdd.tistory.com/216
OR과 AND에서는 하나의 선으로 - 와 + 를 구분할 수 있지만,
XOR 문제에서는 하나의 선으로 -와 +를 구분할 수 없다.
이러한 문제를 해결한 것이 바로 다층 퍼셉트론이다.
2️⃣ 다층퍼셉트론
마빈 민스키 교수가 멀티레이어를 활용하면 XOR 문제를 해결할 수 있다고 하였다.
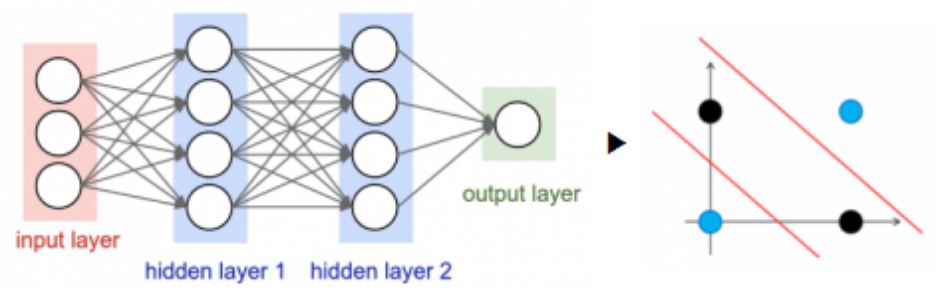
4. 순전파와 역전파

출처: https://numpy.org/numpy-tutorials/content/tutorial-deep-learning-on-mnist.html
1️⃣ 순전파(Forward Propagation)
인공신경망에서 출력층 방향으로 예측값의 연산이 진행되는 과정
입력값은 입력층과 은닉층을 지나면서 각 층에서의 가중치와 함께 연산되며, 츨력층에서 모든 연산을 마친 예측값이 도출된다.
2️⃣ 역전파(Back Propagation)
순전파와 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트 하는 과정
역전파를 통해 가중치 비율을 조정하여 오차 감소를 진행하고 다시 순전파 방향으로 진행하여 오차 감소를 확인한다.
오차역전법은 동일 입력층에 대해 원하는 값이 출력되도록 각각의 가중치를 조정하는 방법으로 사용되며, 속도는 느리지만 안정적인 결과를 얻을 수 있다는 장점이 있어 기계 학습에 널리 사용된다.

출처: 오늘코드 박조은님 강의자료(AIS 7기)
이를 정리하자면, 처음에는 랜덤한 아무 값을 넣어 네트워크를 통과시키고 활성화함수를 적용한 후 Output 값과 실제 값의 오차를 확인한다.
만약 오차가 크다면 역전파로 다시 들어가서 가중치를 조정하게 된다. 이때 역전파에서는 기울기를 구하면서 값을 업데이트하는데, 이로 인해 일부 활성화함수에서는 기울기 소실문제가 발생한다. (미분으로 기울기가 계속 작아지기 때문)
※ 기울기를 구하는 이유는 오차를 계산하기 위함이다.
순전파 -> Input을 받고 다수의 hidden layer에서 활성화함수 적용을 통하여 output을 출력하는 과정
역전파 -> 순전파 과정에서 출력한 결과와 정답값의 오차를 측정하여 그 오차의 값을 최소화하기 위한 과정
5. 활성화 함수
실제 뇌과학에서 뉴런의 전위가 일정치 이상 되면 시냅스가 활성화되어 서로 화학적으로 연결된다.
이처럼 DL에서 시냅스의 역할을 하는 것이 바로 활성화함수이다.
활성화 함수는 은닉층과 츨력층의 뉴런에서 출력값을 결정하는 함수로 가중치를 생성한다.
입력값들의 수학적 선형결합을 다양한 형태의 비선형 결합으로 변환하는 역할을 한다.

출처: https://medium.com/datathings/dense-layers-explained-in-a-simple-way-62fe1db0ed75
1️⃣ sigmoid

S자형 곡선 또는 시그모이드 곡선을 갖는 수학함수

모델 제작에 필요한 시간을 줄인다는 장점이 있지만,
미분 범위가 짧아 정보가 손실되는 기울기 소실현상이 발생한다.
범위: [0,1]
로지스틱 회귀, 이진분류 등에 사용한다.
(이진분류에서 사용한 다음 보통 argmax로 분류를 확정한다.)
2️⃣ tanh
S자형태의 활성화함수이며
일정 범위를 벗어났을 때 기울기가 0이 되어 기울기 소실(gradient Vanishing)문제 발생
상대적으로 빠름
범위: [-1,1]
tanh가 sigmoid보다 범위가 넓기 때문에 조금 더 낫다.
🤔 기울기 소실?
깊은 인공 신경망 학습 시 연전파 과정에서 입력층으로 갈수록 기울기가 점차 작아지는 현상
(ANN 신경망의 문제점으로 대두)
기울기 소실문제 해결방안: ReLU
분류와 회귀에서 사용하는 활성화 함수 종류
1️⃣ 분류
- 이진분류: sigmoid
- 다중분류: softmax
2️⃣ 회귀
항등함수
[참고]
오늘코드 박조은 강사님 수업자료(AIS 7기)
봉수골 개발자 이선비님의 Tensorflow 101 강의 내용
'머신러닝과 딥러닝 > DL 개념정리' 카테고리의 다른 글
| [DL] 6. ImageNet과 ILSVRC 우승 알고리즘 (0) | 2022.12.08 |
|---|---|
| [DL] 3. ANN과 DNN (0) | 2022.12.08 |

댓글