
멋쟁이 사자처럼 AI스쿨 7기 박조은 강사님의 수업내용 및 자료를 바탕으로 포스팅하였습니다.
이전에는 추상화된 도구로 기술통계를 구하는 방법에 대해 배워보았다.
이번에는 도구를 사용하지 않고 직접 기술통계를 구하는 방법에 대해 배워볼 예정이다.
(사용 라이브러리: pandas, numpy, seaborn, matplotlib)
추상화된 도구를 사용하면, 주로 확인하는 기술통계 값을 한꺼번에 확인할 수 있어서 간편하다.
그런데 왜 직접 기술통계를 구하는 것일까?
1. 대용량 데이터의 경우 추상화된 도구를 사용하기 어렵다.
2. 큰 용량의 데이터로 리포트를 출력하고자 할 때 시간이 오래걸린다.
즉, 추상화된 도구는 간편하기는 하지만 대용량의 데이터에는 부적절하며
직접 기술통계를 구할 경우에 보다 세밀하게 컨트롤하여 값을 볼 수 있다.
추상화된 도구로 기술통계 한꺼번에 구하는 방법 보러가기
1. 기술통계 직접 구하기 기초
가. 데이터셋 결측치 확인하기

(오른쪽 사진 처럼, 빨간색 밑줄 친 데이터는 6개의 결측치가 있음을 확인할 수 있다.)
- 데이터셋명.isnull()
- 데이터셋명.isnull().sum(): 결측치의 합계
- 데이터셋명.isnull().mean() * 100: 결측치 비율로 보기 (※ 합/전체 도수 = 평균)
- 데이터셋명.count(): nan 값 제외 개수보기
plt.figure(figsize = (12, 8)) # heatmap을 보다 크게 보기 위한 코드
sns.heatmap(df.isnull(), cmap = "gray")
print(plt.colormaps())
# or print(plt.colormaps())※ cmap = c(olor)map Choosing Colormaps in Matplotlib — Matplotlib 3.6.0 documentation
다. 기술통계
- 데이터명.describe( ): 기술통계값 보기
※ default는 수치형에 대한 기술통계값이다.
※ 수치형: 개수, 평균, 표준편차, 최소값, 최대값, 4분위수
- 데이터명.describe(include = "object"): 범주형 데이터의 기술통계값 보기
※ 범주형: 개수, 고유값, 최빈값(top), 최빈값의 빈도수(freq)
※ 범주형과 수치형의 기술통계 값은 다르다.
- 데이터명.describe(include = "all"): 수치형과 범주형 데이터 출력
- 데이터명.describe(exclude = "object"): 수치형 데이터 출력( = 범주형을 제외하고 출력)
- 데이터명["컬럼(변수)명"].describe( ): 지정한 변수에 대한 기술통계값 보기
※ 값들이 수치형 데이터라면 수치형 데이터의 기술통계 값을, 범주형이라면 범주형 데이터의 기술통계 값을 출력
- 데이터명["수치형변수명"].astype(str).describe( ): 타입 변경 후 범주형 기술통계 값 보기
- 데이터명["수치형변수명 1", "수치형변수명2"].astype(str).describe( ): 두 개 함께 보는 것도 가능(dataframe형태로 출력)
2. 수치형 데이터 기술통계 직접 구하기
가. 수치형 변수
- 데이터명.nuniqe( ): 데이터 내 고유값의 개수를 출력
※ unique( ): 고유값을 출력한다.
※ 데이터명["변수명"].unique( ): 변수명을 콕 집어서 고유값을 출력할 수 있다.
- histogram 그리기
df.hist(figsize=(12, 10), bins=50)
plt.show() # 로그를 삭제해준다.
# 또는 df.hist(figsize=(12, 10), bins=50); 으로도 로그를 삭제할 수 있다.
나. 왜도(비대칭도)

[참고문서] 비대칭도 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
- 실수 값 확률변수의 확률 분포 비대칭성을 나타내는 지표
- 양수나 음수가 될 수 있고 정의되지 않을 수도 있다.
- 음수일 경우 확률밀도함수의 왼쪽 부분에 긴 꼬리를 가지며 중앙값을 포함한 자료가 오른쪽에 더 많이 분포해 있다.
- 양수일 경우 확률밀도함수의 오른쪽 부분에 긴 꼬리를 가지며 자료가 왼쪽에 더 많이 분포해 있다.
- 평균과 중앙값이 같으면 왜도는 0이다.
- 데이터명.skew( ): 전체 수치변수에 대하여 왜도 출력
※ 값 정렬하기: 데이터명.skew( ).sort_values( )
다. 첨도
[참고문서] 첨도 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
- 확률분포의 꼬리가 두꺼운 정도를 나타내는 척도
- 극단적인 편차 또는 이상치가 많을 수록 큰 값을 나타낸다.
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가깝다.
- 3보다 작을 경우에는(K<3) 산포는 정규분포보다 꼬리가 얇은 분포로 생각할 수 있다
- 첨도값이 3보다 큰 양수이면(K>3) 정규분포보다 꼬리가 두꺼운 분포로 판단할 수 있다.
- 데이터명.kurt( ): 전체 수치변수에 대하여 첨도 출력
※ 값 정렬하기: 데이터명.skew( ).sort_values( )
※ sort_values(ascending = False): 내림차순 정렬
+ agg
- agg를 사용하면, 다양한 통계값을 구할 수 있다.
- 데이터명["변수명"].agg(["skew", "kurt", "mean", "median"])
※ agg를 활용하여 원하는 변수에 대한 왜도, 첨도, 평균, 중앙값을 구한 코드이다.
기술통계에 대한 기본 내용을 익혔다면, 이번에는 그래프를 그리는 방법에 대해 배워보겠다.
(데이터 셋을 불러오는 방법은 이전 글을 참고하자.)
seaborn 라이브러리를 활용하여 그래프를 그릴 예정이다.
seaborn 공식문서는 아래 링크에서 확인하며, 관련 내용은 다른 게시글로 심도있게 배워보도록 하겠다.
[seaborn] https://seaborn.pydata.org/

3. 1개의 수치 변수에 대하여 그래프 그리기
가. displot(기본 값 count)
- sns.displot(data = 데이터명, kde = True) : displot을 통해 히스토그램과 kdeplot 그리기
※ 데이터 전체에 대한 그래프로 시각화가 잘 되어 있다고 보기 어렵다.

- sns.displot(data=데이터명, x = "x 축 변수", kde = "True")
※ kde는 히스토그램의 확률밀도함수로 true로 설정할 경우 출력하며, false로 설정하면 미출력된다.
※ x 축을 지정할 수 있으며, 지정하면 보다 세부적으로 그래프를 볼 수 있다.

- sns.displot(data = 데이터명, x = "x축변수", kde = "True", hue = "hue변수", bins = 50)
※ hue는 groupby와 같은 개념이다. 어떤 기준으로 분류하여 색깔을 나눌지 설정할 수 있다.
※ 참고로 col 을 지정하는 것도 있는데, 이는 subplot을 생성하는 것을 의미한다.

나. boxplot
※ 전체 변수가 함께 나와 있어서 한 눈에 보기 어렵다.

- sns.boxplot(data = 데이터명, x="변수명"): x축에 변수를 지정하여 해당 변수에 대한 상자수염그림을 표현

※ 상자수염그림은 뭘까?
https://ko.wikipedia.org/wiki/%EC%83%81%EC%9E%90_%EC%88%98%EC%97%BC_%EA%B7%B8%EB%A6%BC

<kedplot, rugplot으로 밀도함수 구하기>
- sns.kdeplot(data = 데이터명, x="변수명"): kdeplot으로 밀도함수를 표현
- sns.rugplot(data = 데이터명, x="변수명"): rugplot으로 밀도함수를 표현
다. Violinplot
- sns.violinplot(data = 데이터명) : 전체 변수에 대하여 violinplot을 출력
※ 전체 변수에 대한 그래프로 한 눈에 보기 어렵다.

- sns.violinplot(data = 데이터명, x="변수명") : x 축을 지정함으로써 해당 변수에 대한 violinplot을 출력한다.

모양에서 유추할 수 있겠지만, violinplot은 kdeplot 2개를 합쳐놓은 plot이다.
(그리고 kdeplot은 히스토그램의 확률밀도이다.)
그럼 전체 변수에 대해 violinplot 그리고 싶을 경우엔 어떻게 해야할까?
바로, 정규화를 거친 후 plot을 그려주면 된다.
* 정규화 = (관측치 - 평균) / 표준편차
데이터명_num = 데이터명.select_dtypes(include="number") # 수치형 데이터만 출력
데이터명_std = (데이터명_num - 데이터명_num.mean()) / 데이터명_num.std() # 표준화
- sns.violinplot(data = 데이터명_std)
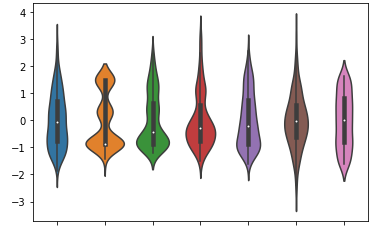
정규화를 거쳐서 그래프를 그려주면, 깔끔하게 볼 수 있다.
4. 2개의 수치 변수에 대하여 그래프 그리기
지금까지 1개의 수치 변수에 대하여 그래프를 그리는 방법에 대해 알아보았다.
이제는 2개의 수치변수에 대하여 그래프를 그리는 방법에 대해 알아보자.
가. scatterplot

- sns.regplot(data = 데이터명, x="x축 변수명", y="y축 변수명") : 산점도 + 회귀선을 표현해주는 그래프이다.


다. lmplot과 jointplot
※ kind는 여러 옵션으로 지정 가능하다. ex) kde, line, hex ...
- sns.lmplot(data = 데이터명, x="x축 변수", y="y축 변수", hue="hue 변수", col="subplot으로 그릴 변수")
: 범주값에 따라 색상, 서브플롯 그리기
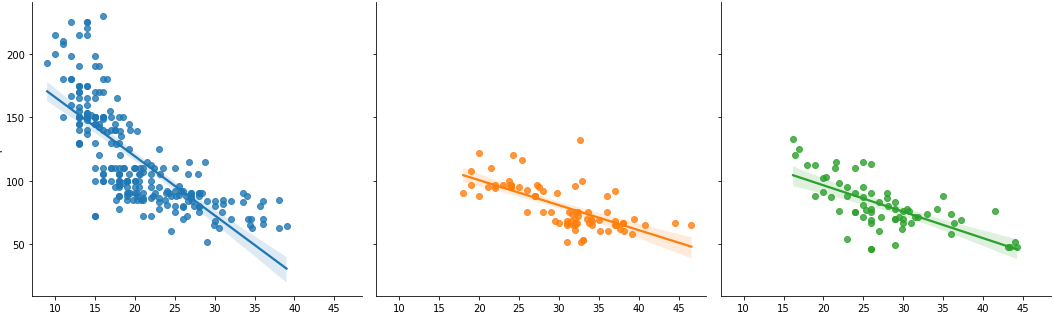
언뜻 보기에는 hue와 col의 역할이 비슷해보인다.
위에서도 언급한바가 있지만, hue는 groupby와 같은 역할을 한다.
hue는어떤 기준으로 색깔을 구분해서 나눌 것인지의 역할이다.
col은 어떤 기준으로 subplot을 그릴 것인지를 의미한다. (subplot이란 하나의 실행 값에 여러 개의 plot을 출력하는 것이다.)

즉, 만약 hue만 입력을 해주었다면 위와 같이 여러 색깔을 가진 그래프가 하나의 그림으로 출력되었을 것이다.
※ lmplot과 regplot
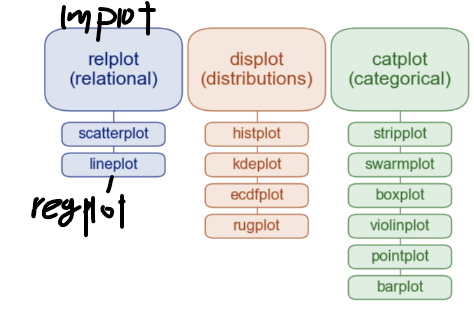
seaborn 공식문서 표에 lmplot과 regplot이 빠져 있어서 추가로 그려넣었다.
lmplot은 regplot의 상위 개념으로 regplot은 scatterplot과 lineplot을 합쳐 놓은 그래프다. (위에서 regplot을 그려봤으니 참고)
다만, lmplot은 hue 옵션을 이용해 색깔을 분리해 그릴 수 있지만, regplot은 hue 옵션 사용이 불가능하다.
라. pairplot
pairplot은 2개의 변수에 대해 짝을 지어 시각화하는 plot이다.
- sns.pairplot(data = 데이터명.sample(100))
※ pairplot은 그리는데 시간이 오래걸리기 때문에 100개의 샘플을 추출하여 그려보았다.
- sns.pairplot(data = 데이터명.sample(100), hue="변수명")
※ hue 옵션도 지정 가능하다.
마. lineplot
- sns.lineplot(data = 데이터명, x="x축 변수", y="y축 변수")

사. relplot
- sns.relplot(data = 데이터명, x="x축 변수", y="y축 변수", hue="변수")

- sns.relplot(data = 데이터명, x="x축 변수", y="y축 변수", kind="line")

- sns.relplot(data = 데이터명, x="x축 변수", y="y축 변수", hue="변수", col="변수", kind="line", ci=None)
※ ci는 신뢰구간을 의미, None으로 지정하면 신뢰구간을 제외하고 출력한다.

※ relplot과 lineplot
relplot과 lineplot의 차이는, lmplot과 regplot의 차이와 유사하다.
보통 relplot은 subplot을 그리기 위해서 사용한다.
서브플롯을 그릴 수 있는 것: relplot, lmplot
서브플롯을 그리지 못하는 것: lineplot, regplot

※ subplot과 관련하여
scatterplot, lineplot 등의 subplot을 그릴 때 : relplot
histplot, kdeplot 등의 subplot을 그릴 때: displot
boxplot, violinplot 등의 subplot을 그릴 때 : catplot
즉, 상위 plot으로 올라가서 subplot을 사용하면 된다.
5. 상관분석
- 데이터명.corr(): 상관계수 구하기 함수
# np.triu : matrix를 상삼각행렬로 만드는 numpy math
# [1 2 3] np.triu [1 2 3]
# [4 5 6] -------> [0 5 6]
# [2 3 4] [0 0 4]
# np.ones_like(x) : x와 크기만 같은 1로 이루어진 array를 생성
mask = np.triu(np.ones_like(corr))sns.heatmap(corr, cmap="coolwarm", annot=True, mask=mask)
[참고1]
1. 라이브러리 버전 확인하는 방법
print(pd.__version__)!pip install seaborn --upgrade※ 새로운 버전으로 보이지 않는다면, 런타임을 다시 시작할 것
[참고2]
주석 추가하고 빼는 단축키: ctrl(cmd) + /
'Python > 개념정리' 카테고리의 다른 글
| [Python] 9. 웹스크래핑 (3) - read_html(), trange, time.sleep() (0) | 2022.10.30 |
|---|---|
| [Python] 7. 웹스크래핑(1) - 기본개념, 주의사항 (0) | 2022.10.30 |
| [Python] 4. EDA(1) - pandas profiling, sweetviz, autoviz (0) | 2022.10.26 |
| [Python] 3. 함수 (0) | 2022.10.26 |
| [Python] 2. 제어문(조건문, 반복문) (1) | 2022.10.26 |

댓글