
1. group by
split - apply - combine
1️⃣ split: 몇가지 기준에 따라 데이터를 그룹으로 분할한다.
2️⃣ applying: 각 그룹에 독립적으로 함수를 적용한다.
3️⃣ combining: 결과를 데이터 구조로 결합한다.
적용단계에서 할 수 있는 것들
1️⃣ 집계
각각에 대한 요약 통계(또는 통계)를 계산
그룹의 합계, 평균
그룹의 크기, 개수
2️⃣ 변환
일부 그룹 별 계산을 수행하고 같은 인덱싱된 개체
그룹 내에서 데이터(zscore)를 표준화
그룹 내의 NA를 각 그룹에서 파생된 값으로 채운다.
3️⃣ 필터링
그룹별 계산에 따라 일부 그룹 삭제 참 또는 거짓을 평가
구성원이 소수인 그룹에 속한 데이터를 삭제합니다.
그룹 합계 또는 평균을 기준으로 데이터를 필터링합니다
(1) split
한 가지 기준 또는 두 가지 기준 등으로 그룹화
grouped = df.groupby("A")
grouped = df.groupby(["A", "B"])
열에 multi-index가 있는 경우에도 그룹화가 가능하다.
df2 = df.set_index(["A", "B"])
grouped = df2.groupby(level=df2.index.names.difference(["B"]))
정렬기준 설정하기
grouped = df.groupby(by = "A", sort = False)
grouped = df.groupby(by = ["A", "B"], sort=[False, True])
그룹화 한 다음에 특정 컬럼만 가져올 수도 있다.
grouped = df.groupby(by = ["A", "B"], sort=[False, True])["C"]
(2) applying
grouped = df.groupby("A").sum()
grouped = df.groupby(by = ["A", "B"], sort=[False, True])["C"].sum()
사용할 수 있는 함수의 종류
| mean() | 그룹의 평균 계산 |
| sum() | 그룹 값의 합계 계산 |
| size() | 컴퓨팅 그룹 크기 |
| count() | 그룹의 계산 수 |
| std() | 그룹의 표준 편차 |
| var() | 그룹의 분산 계산 |
| sem() | 그룹 평균의 표준 오차 |
| describe() | 기술 통계 생성 |
| first() | 그룹 값의 첫 번째 계산 |
| last() | 그룹 값의 마지막 계산 |
| nth() | n 번째 값을 가져 오거나 n이 목록 인 경우 하위 집합을 가져옵니다. |
| min() | 그룹 값의 최소 계산 |
| max() | 그룹 값의 최대값 계산 |
여러개의 함수를 적용해볼 수도 있다.
- agg 사용
df.groupby(by = "C")["D"].agg([np.sum, np.mean, np.std])
df.groupby(by = "C")["D"].agg(["count", "sum"])
+ 이렇게도 사용할 수 있다.
Q. 년도별 각컬럼의 평균값을 구하여라
df5.groupby(df5["Yr_Mo_Dy"].dt.year).mean()
문제출처: 판다스 연습 튜토리얼 — DataManim
(3) group by 실습
# 소비자물가지수의 연간 최대값
pd.DataFrame(df910.groupby(["지출목적명", "연도"])["소비자물가지수"].max())
# desc = df.groupby("dataset")[["x", "y"]].describe()
desc = df.groupby("dataset").describe()
desc
2. pivot과 pivot_table
pivot과 pivot_table의 차이는 집계 가능 여부이다.
pivot은 집계가 불가능 하고
pivot_table은 집계가 가능하다.
(1) pivot_table 사용방법
pandas.pivot_table(data, values=None, index=None,
columns=None, aggfunc='mean', fill_value=None, margins=False,
dropna=True, margins_name='All', observed=False, sort=True)
(2) pivot_table 주요 파라미터
data
DataFrame
pivot_table을 적용할 데이터프레임
values
column to aggregate, optionali
적용될 값, 합쳐져야 할 경우 평균이 기본값이다.
values = age, aggfunc = sum 지정할 경우 나이의 합계가 출력된다.
index
column, Grouper, array, or list of the previous
지정할 인덱스 입력(행에 입력될 값)
columns
column, Grouper, array, or list of the previous
컬럼(열)으로 사용할 값
만약, sex를 columns로 지정하면
female, male 형태로 피벗테이블이 생성된다.
aggfunc
function, list of functions, dict, default numpy.mean
pivot에 적용할 함수
['mean', 'sum'] 처럼 동시에 2개의 함수도 지정할 수 있다.
fill_value
scalar, default None
NaN값 채울지 여부
margins
bool, default False
dropna
bool, default True
margins_name
str, default ‘All’
observed
bool, default False
sort
bool, default True
(3) pivot_table 실습
alive 별로 age의 평균 값 구하기
df.pivot_table("age", index = "alive")
df 데이터에서 cut을 인덱스로, 컬럼을 color로 지정하고 price의 합계 값 구하기
pd.pivot_table(data = df, values = "price", index = "cut", columns = "color")
loc를 사용하면 열 순서를 바꿀 수 있다.
pt = pd.pivot_table(data = df, values = "price", index = "cut", columns = "color")
pt.loc[["Fair", "Premium", "Good", "Very Good", "Ideal"]]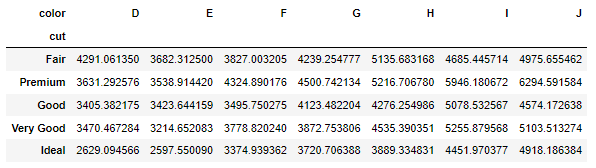
+ 또 다른 실습
[문제출처] 판다스 연습 튜토리얼 — DataManim
년도에 따른 medal 갯수를 데이터프레임화 하라
df62.pivot_table(index='Year',columns='Medal',aggfunc='size').fillna(0)
(4) pivot
[문제출처] 판다스 연습 튜토리얼 — DataManim
Q. 나라에 따른 년도별 사망률을 데이터 프레임화 하라
ans.pivot(index = "Location", columns = 'Period', values = "First Tooltip")
참고
Group by: split-apply-combine — pandas 1.5.1 documentation
Group by: split-apply-combine By “group by” we are referring to a process involving one or more of the following steps: Splitting the data into groups based on some criteria. Applying a function to each group independently. Combining the results into a
pandas.pydata.org
pandas.pivot_table — pandas 1.5.1 documentation (pydata.org)
pandas.pivot_table — pandas 1.5.1 documentation
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers. Changed in version 0.25.0.
pandas.pydata.org
[Pandas 기초] 피벗 테이블(pivot_table)과 멀티인덱스(MultiIndex) - yg’s blog (yganalyst.github.io)
[Pandas 기초] 피벗 테이블(pivot_table)과 멀티인덱스(MultiIndex)
판다스의 피벗테이블과 그에 따라 생기는 멀티인덱스에 대해 알아보자
yganalyst.github.io
'Python > Pandas' 카테고리의 다른 글
| [Python] Pandas - 18. map(), apply(), applymap() (1) | 2023.11.13 |
|---|---|
| [Python] Pandas - 10. 구간 나누기(cut, qcut) (0) | 2022.10.26 |
| [Python] Pandas - 9. dt접근(datetime) (0) | 2022.10.26 |
| [Python] Pandas - 8. value_counts(빈도수 확인), sort_(정렬하기) (0) | 2022.10.26 |
| [Python] Pandas - 7. 데이터프레임 원하는 값만 출력하기 (0) | 2022.10.26 |

댓글