
1. 컬럼, 컬럼값 추가하기
세로로 한 줄 추가된다.
1) 컬럼명과 값 직접 입력해서 추가하기
import pandas as pd
df_grade = pd.DataFrame()
df_grade["이름"] = ["김가영", "정나영", "이다영"]값을 하나만 입력할 경우 해당 컬럼에 하나의 값이 일괄적으로 입력된다.
df_grade["나이"] = 25나이 컬럼에 25가 일괄적으로 입력될 것이다.
2) insert로 추가하기
중간에 컬럼을 추가하고 싶은 경우 insert( ) 활용
insert(컬럼 인덱스, 컬럼명, 값)2. 컬럼값 변경하기
위에서 나이 컬럼에 일괄적으로 25라는 값이 입력되었기에 나이 컬럼 값을 바꿔보자.
df_grade["나이"] = [27, "nan", 28]nan 값을 입력할 수도 있다. (nan은 not a number의 약자)
nan의 데이터 타입은 float이다.
3. 컬럼명 변경하기
데이터프레임.rename(columns = {'old' : 'new'})
데이터프레임.rename(columns = {'old' : 'new'}, inplace = True)4. 컬럼, row 삭제하기
1) 컬럼 삭제
drop: 컬럼을 잘못추가했거나 삭제하고자 할 때 사용
drop(axis = 0 or 1): 0은 행, 1은 열을 의미 (컬럼 삭제 시에는 반드시 axis = 1을 지정해야 한다.)
# 성별2 컬럼 삭제하기
df_grade["성별"] = "남자"
df_grade["성별2"] = "여자"
df_grade = df_grade.drop("성별2", axis = 1)
df_grade['성별','나이'] # 다수의 컬럼도 삭제 가능2) columns = " "을 지정하여 컬럼 삭제하기
df = df.drop(columns = "Unnamed: 133")여러개를 한꺼번에 삭제도 가능하다.
df = df.drop(columns = ["지출목적별", "항목", "단위", "단위", "날짜"])
3) 행 삭제하기
행 삭제시에는 index를 지정하여 삭제한다.
df_grade.drop(1)
df_grade.drop(np.arange(2)) # 범위를 지정해서 삭제할 수도 있다.
df_grade.drop([1,3]) # fancy indexing을 활용해서 삭제할 수도 있다.3) 변경된 결과 바로 적용하기
df_grade.drop([1,3], inplace = True)inplace를 사용하지 않은 경우,
변경된 값을 저장하려면 변수에 재할당해주어야 한다.
5. 컬럼 순서 변경하기
df_seoul_fin = df_seoul_new[["시도별", "지출목적코드", "지출목적명", "연도", "월", "소비자물가지수"]]6. 컬럼(값)간 연산하기
# df 데이터프레임 복제
df_grade = df_grade.copy()df_grade['info'] = df_grade['이름'] + df_grade['나이']
# 중간에 '-' 등 문자열도 합칠 수 있다.
df_grade['info'] = df_grade['이름'] + '-' +df_grade['나이']연산시 1개의 컬럼이라도 NaN값을 포함하고 있다면 결과는 NaN이 된다.
7. 인덱스 지정하기
set_index("컬럼명") 로 인덱스를 지정할 수 있다.
인덱스란 행의 대표 정보이다. (= 컬럼 값을 인덱스로 변환) 즉, 컬럼명 중 하나로만 지정이 가능하다.
df_grade.index
# "이름"을 인덱스로 지정하기
df_grade.set_index("이름")
# "이름"을 인덱스로 지정한 후 인덱스 출력하기
df_grade.set_index("이름").index
# "이름"을 인덱스로 지정한 후 이름이 "김가영"인 행 출력
df_grade.set_index("이름").loc["김가영"]
8. 인덱스 삭제하기
1) reset_index()
인덱스(명)가 index로 리셋된다.
(단, 두번 하면 level_0 등등으로 늘어난다.)
# 인덱스리셋(인덱스명이 index로 정정됨)
df_grade = df_gread.reset_index()
# reset을 실행하면 실행 횟수 만큼 인덱스가 늘어난다. (index, level_0, level_1 ...)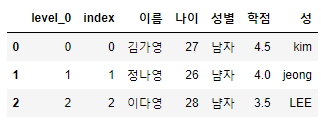
2) 인덱스 삭제
del 데이터프레임명["인덱스명", axis = 1]
※ 컬럼이나 행 값을 삭제하는 경우엔, del과 drop을 사용했었다.
del df_grade["index"]
del df_grade["level_0"]
# df_grade = df_grade.drop("index", axis = 1)
# df_grade = df_grade.drop(["index", "level_0"], axis = 1)
# 2번 삭제하려는 경우 - del은 2번 작성해야 하지만, drop은 1번으로 함께 삭제할 수 있다.
9. 중복 제거하기
1) 중복 값 불 타입으로 확인하기
df.duplicated()
불 값으로 나타내준다.
2) 중복 값만 뽑아내기
df[df.duplicated()]
불리언 인덱싱으로 중복값만 데이터프레임으로 만들어준다.
3) 중복값 제거
df.drop_duplicates()
*파라미터: subset, keep 등
10. 파생변수 만들기
df_grade["성_대문자(파생변수)"] = df_grade["성"].str.upper()# "성_대문자" 컬럼에서 "KIM|LEE" 값이 들어가는 문자를 찾아보기
df_grade["성_대문자(파생변수)"].str.contains("KIM|LEE")
df_grade[df_grade["성_대문자(파생변수)"].str.contains("KIM|LEE")]'Python > Pandas' 카테고리의 다른 글
| [Python] Pandas - 8. value_counts(빈도수 확인), sort_(정렬하기) (0) | 2022.10.26 |
|---|---|
| [Python] Pandas - 7. 데이터프레임 원하는 값만 출력하기 (0) | 2022.10.26 |
| [Python] Pandas - 5. 데이터프레임 출력, 타입, 전치, 미리보기, 기술통계, 통계값(집계/상관계수 등) (0) | 2022.10.26 |
| [Python] Pandas - 4. 데이터프레임 기본개념, 생성, 인덱싱과 슬라이싱(출력) (0) | 2022.10.26 |
| [Python] Pandas - 3. 시리즈 어트리뷰트와 메서드 (0) | 2022.10.26 |

댓글